
Step by Step Guide to Build a Data Mining Project

Step 1: Understand the Project Objectives
Before starting any data mining project:
- It is crucial to understand the requirement and objectives of the project and decide whether data mining can be applied to meet the goals.
- Another thing to determine is what nature of data needs to be collected to create a deployable model.
Now, this understanding can then be used for initial data collection.
Step 2: Understand the Data
Once we have collected our initial data:
- We need to ensure that it is suitable for use before processing it.
- If the data is poor in quality, we need to collect more data or change the process of data collection using more precise and thoughtful rules.
The next step should be getting initial insights from our collected data and reviewing the project’s objective.
The vital question in this step is, “Can DM be applied to this data?“.
Step 3: Prepare the Data
Once we are happy with the data, the next step will be preprocessing the data so that Machine Learning algorithms can be applied. Preprocessing steps comprise Data Cleaning and different transformations.
Data Cleaning
This is the most tedious step for real-world data since there may be a lot of issues during data collection. In real-world,
- Data may have missing values or is incomplete
- Data contains noise, e.g., errors and outliers
- Data may have inconsistency, e.g., incorrect names.
The data cleaning process involves finding and filling in those missing/ incomplete values, removing or smoothing the noisy data, identifying the outliers, and resolving all the inconsistencies.
Transformation
This step involves converting data into standard formats, transforming data into new formats, performing normalization, reducing dimensionality, and selecting data features for modeling.
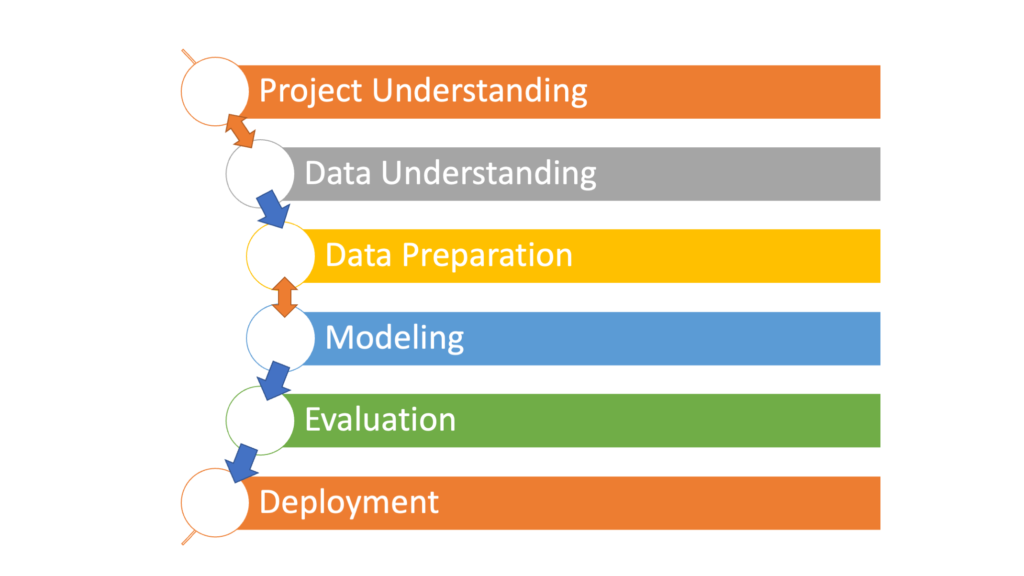
Step 4: Modelling
This step involves building models that perform different types of tasks on data to generate insights.
Main Task of Data Mining
There are two main types of tasks:
- The Classification and Regression tasks are a part of supervised learning.
- The Clustering task is part of Unsupervised learning.
Other tasks include:
- Reinforcement Learning.
- Association Rule Mining.
- Outlier Detection etc.
Modeling is done concurrently with Data Preparation. There are several iterations between these steps. E.g., The output from the model may inform us to use some different preprocessing, like using other features and building the model again.
Step 5: Evaluation
This is one of the most crucial steps of any Data Mining Project. The model we build should be evaluated so that we may know how good our performance is.
- For this, we can use measures like the Accuracy measure, F1 measure, etc.
- The next thing to check is whether or not our data has produced some meaningful and sound patterns.
- If the performance of our model is not good, we need to reconsider the project understanding and jump back to the First step.
- Suppose our performance is good enough. We can deploy that model in practice.