
Data Explosion: Data Mining vs Machine Learning

Why do we have so much data?
The past few decades have shown a tremendous increase in data, often referred to as the “Data Explosion.” Human civilization has not only started producing more data but has found means to store such vast amounts of data. This “Data Explosion” phenomenon is ramified for several reasons, e.g.,
- cheaper and more powerful computers,
- advanced database management technology,
- automated data collection tools, and sensors.
Interestingly with such advancement, the data explosion has not limited itself to one or two fields but has spread across all the existing domains, from science to business to economics, medicine, environment, earth sciences, etc.
Who is producing so much data?
Let’s understand how we are producing such a massive amount of data.
- Take the example of online E-commerce, supermarts, or any department store; all this business collects their customers’ purchase data. The development of advanced database management systems and cheap computers has replaced labor-intensive/manual tasks with few clicks of a button.
- Similarly, bank and credit card companies track our spending/earning data.
- Then, we have telephone companies that store call details and government agencies collecting and storing various national data.
- New scientific instruments and technology have also contributed significantly to the data explosion. Hubble telescope scanning the entire skies, thousands of satellites launched into earth orbit each year, thousands of millions of people going to medical scans and checkups, and several seismometers spreading across the globe continuously recording earth vibrations are just a few of the examples that are piling heaps and heaps of data daily.

What is Data Mining?
The ongoing trend of gathering whatever data, whenever and wherever possible, based on a vision that our data might be useful in a way we cannot yet imagine, is interesting. Nevertheless, raw data is not that useful, and therefore we need methods to extract knowledge or pattern from these datasets in a fast, sustainable, and automated manner. Data mining refers to a broader domain of automated or semiautomated techniques used to find practical, meaningful, and applicable insights or patterns from data.
Where is Data Mining used?
Fraud Detection in credit card transactions:
Credit card companies collect data about customers transactions, what they generally buy and when, there demographic and socioeconomic information like age, education, income, etc. This data record can be used to find whether any future transaction is fair or fraudulent.
Weather Forecasting:
Another example can be in a weather forecast; if we have data on temperature, pressure, and humidity, we can predict wind velocity, which can be used in extensive marine and air navigation systems.
Targeted marketing:
Data Mining can be used to segment customers into groups with similar characteristics, like products they often buy or use. Then they can tailor their ad campaign to their target user, saving the companies money.
Data Mining vs Machine learning
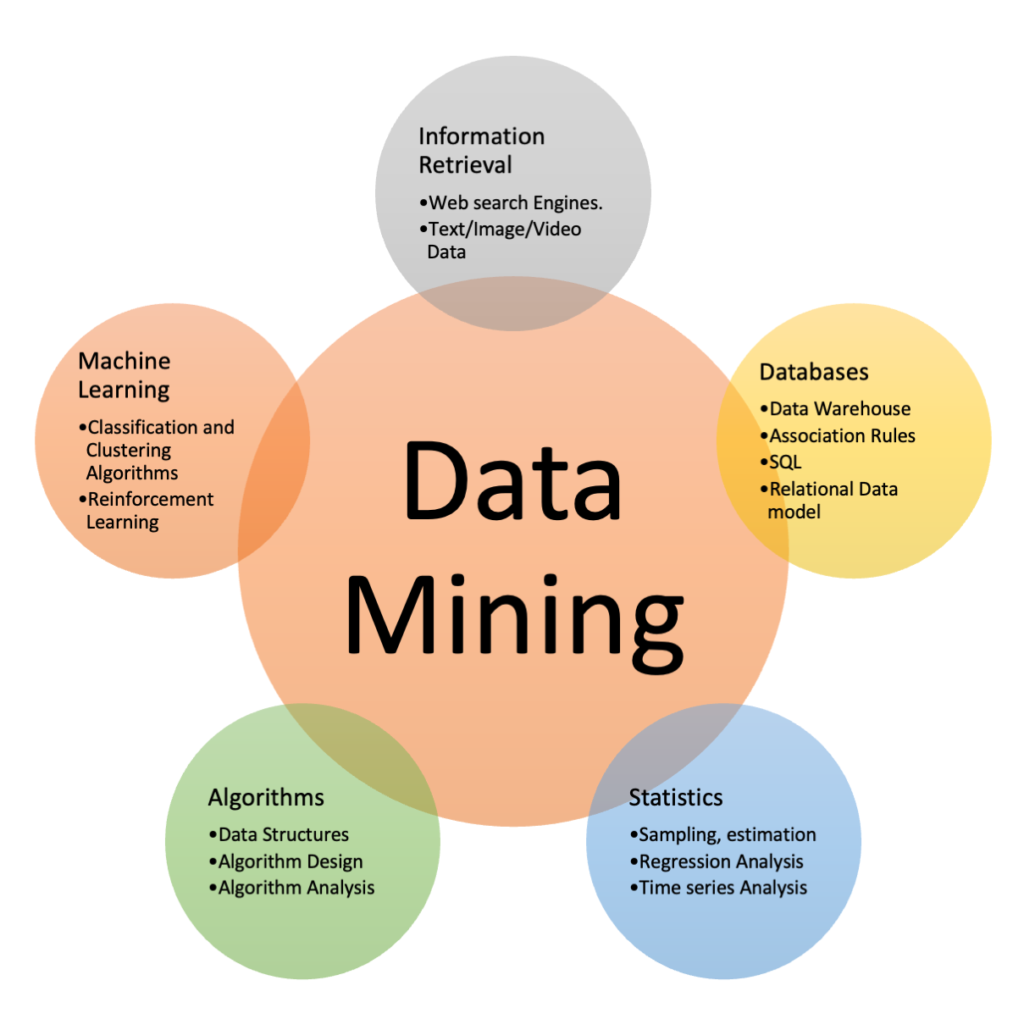
Many may get confused with term “machine learning,” which is often synchronously used with the term “data mining.” However, Machine learning algorithms are a set of tools often used for data mining.
- They are a core part of artificial intelligence, and most of these algorithms were developed for data mining but have several other applications.
- Also, data mining deals with large and multidimensional datasets, but that is not always the case for ML.
- Since we use ML algorithms to perform DM. DM can be seen as applied ML
Data Mining vs Machine learning
Machine learning algorithms are a set of tools that uses sample data called training data to build a model that can be used to make predictions or decisions without explicitly programming them.
They are broadly categorized into three groups:
Supervised Learning: When the algorithm is given a set of label data to learn and generate a model which can be used for predicting outcomes for new data. E.g., ML algorithms are presented data of previous credit card transactions with Fair or Fraud Label. Now the algorithm can build a model using this data to predict whether future transactions are Fair or Fraud.
Unsupervised Learning: When the algorithms try to learn and find patterns without providing labeled data. E.g., An ML clustering algorithm can be used to segment customers based on their buying behavior without any labeled data.
Reinforcement Learning: When the algorithms learn rules in a dynamic environment based on positive or negative feedback received. For every correct output, the algorithms receive a reward, which it tries to maximize in subsequent steps.